MEKA
The MEKA project provides an open source implementation of methods for multi-label learning and evaluation. In multi-label classification, we want to predict multiple output variables for each input instance. This different from the 'standard' case (binary, or multi-class classification) which involves only a single target variable. MEKA is based on the WEKA Machine Learning Toolkit; it includes dozens of multi-label methods from the scientific literature, as well as a wrapper to the related MULAN framework.
Main developers:
- Jesse Read (Ecole Polytechnique, France)
- Peter Reutemann (University of Waikato, New Zealand)
- Joerg Wicker (Johannes Gutenberg University Mainz)


NEW RELEASE March 29, 2019: MEKA's homepage has been moved to GitHub Pages. You should be automatically redirected there now.
NEW RELEASE April 12, 2017: Meka 1.9.1 is released. This release gives several minor improvements and fixes over the previous version, but it also includes new features and new classifiers. See the README regarding changes.
Citing Meka:
@article{MEKA,
author = {Read, Jesse and Reutemann, Peter and Pfahringer, Bernhard and Holmes, Geoff},
title = {{MEKA}: A Multi-label/Multi-target Extension to {Weka}},
journal = {Journal of Machine Learning Research},
year = {2016},
volume = {17},
number = {21},
pages = {1--5},
url = {http://jmlr.org/papers/v17/12-164.html},
}
MEKA in your Java code Dec 08, 2016: Added some examples of how to use Meka in your Java code.
Meka in JMLR-mloss April 29, 2016: Meka published in Journal of Machine Learning Research MLOSS track. You can now cite Meka.
Move to Github Nov 04, 2015: Meka is moving to GitHub. The releases and other files will still be updated at SourceForge.net, but the code repository is now: https://github.com/Waikato/meka.
Meka on Maven Central
To include it in your projects,
<dependency>
<groupId>net.sf.meka</groupId>
<artifactId>meka</artifactId>
<version>1.9.1</version>
</dependency>
Download
Download MEKA at sourceforge.net.
Get a nightly snapshot.
Checkout the code from GitHub:
https://github.com/Waikato/meka.git
Documentation
To get started, download MEKA and run ./run.sh (run.bat on Windows) to launch the GUI.
The MEKA tutorial (pdf) has numerous examples on how to run and extend MEKA.
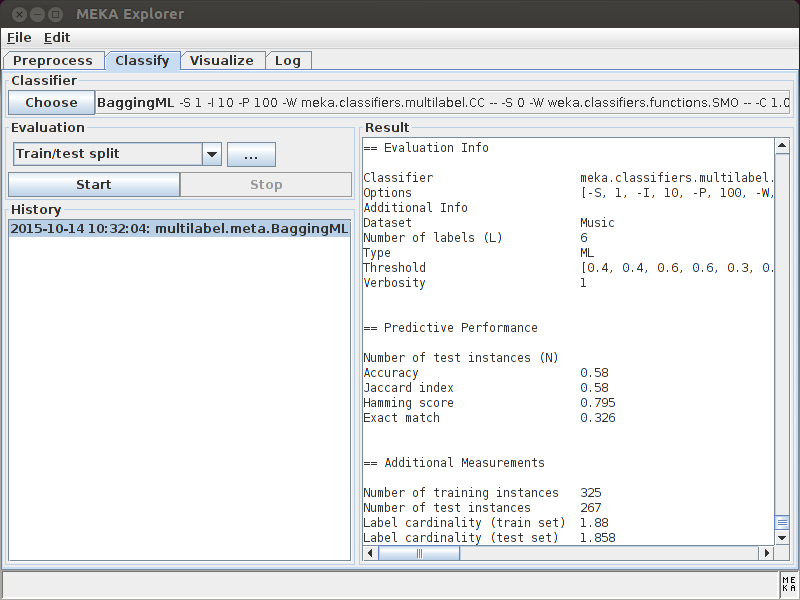
See the list of methods available in MEKA, and (command-line) examples on how to use them.
There are some examples on how to use Meka in your Java code.
The API reference is available.
MEKA originated from implementations of work from various publications (note also the references therein). There are some tutorials/slides about multi-label and multi-target classification in general.
Have a specific problem or query? Post to MEKA's Mailing List (please avoid contacting developers directly for MEKA-related help).
Datasets
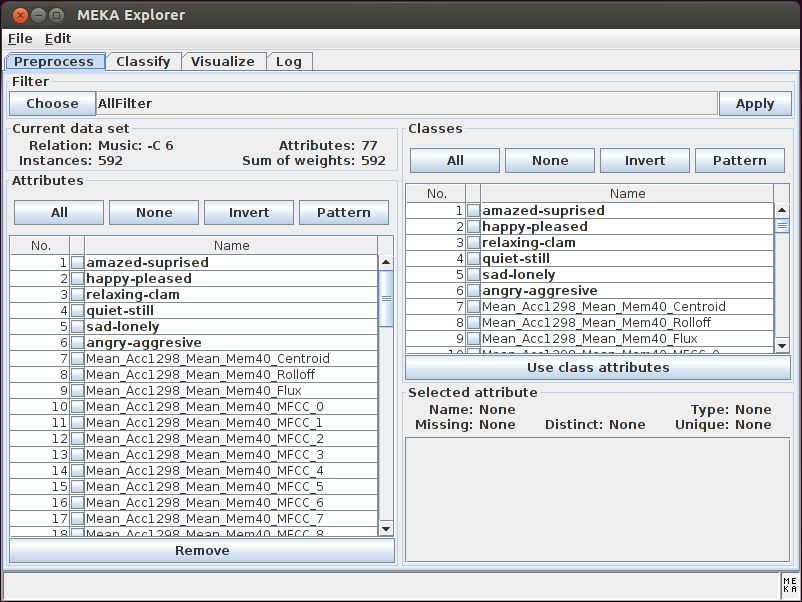
A collection of multi-label and multi-target datasets is available here. Even more datasets are available at the MULAN Website (note that MULAN indexes labels as the final attributes, whereas MEKA indexs as the beginning). See the MEKA Tutorial for more information.
The following text datasets have been created / compiled into WEKA's ARFF format using the StringToWordVector filter. Also available are train/test splits and the original raw prefiltered text.
| Dataset | L | N | LC | PU | Description and Original Source(s) |
| Enron | 53 | 1702 | 3.39 | 0.442 | A subset of the Enron Email Dataset, as labelled by the UC Berkeley Enron Email Analysis Project |
| Slashdot | 22 | 3782 | 1.18 | 0.041 | Article titles and partial blurbs mined from Slashdot.org |
| Language Log | 75 | 1460 | 1.18 | 0.208 | Articles posted on the Language Log |
| IMDB (Updated) | 28 | 120919 | 2.00 | 0.037 | Movie plot text summaries labelled with genres sourced from the Internet Movie Database interface, labeled with genres. |
N = The number of examples (training+testing) in the datasets
L = The number of predefined labels relevant to this dataset
LC = Label Cardinality. Average number of labels assigned per document
PU = Percentage of documents with Unique label combinations
Links
Other software that uses MEKA
- ADAMs framework - integrates MEKA into workflows
- MOA environment for data streams can use Updateable MEKA classifiers
- scikit-multilearn can interface to MEKA in Python
- KNIME framework, includes a plugin to integrate Meka Classifiers into workflows
- DKPro Text Classification Framework
Other multi-label links
- MULAN Framework for Multi-label Classification
- Mulan Multi-label Group from the Machine Learning and Knowledge Discovery Group in the Aristotle University of Thessaloniki.